In this article
- Why standard attribution models fail for 18-month scientific buying cycles.
- How to choose between U-shaped, W-shaped, and full-path attribution.
- How to build a Universal Index so the same researcher is recognised across every channel.
- How to define high-intent vs low-intent signals in a Life Science context.
- How to sync your CRM and Business Intelligence (BI) tools into a reporting environment your sales colleagues will trust.
- Why measuring incremental influence matters more than assigning credit.
A researcher downloads a validated protocol in March and they attend a webinar in July. Then in October, they request a technical consultation. By the time a purchase order arrives the following spring, those interactions exist in separate systems, attributed to three different sources, and credited to two different teams who have never compared notes.
This is the attribution problem in Life Sciences marketing. In diagnostics, MedTech, and laboratory equipment, buying decisions typically involve a prolonged vendor evaluation process spanning 9 to 24 months [1]. Marketers cannot accurately evaluate an 18-month buying journey through a single touchpoint. The challenge is not a lack of tracking tools, but a lack of continuity across a journey that spans multiple stakeholders, systems, channels and sales interactions.
This article sets out a practical framework for closing that gap. It covers how to choose the right attribution model for a long scientific buying cycle, how to build a shared identifier strategy so the same researcher is recognised across every touchpoint, and how to connect your CRM and BI tools into a reporting environment that sales and leadership will actually trust.

Why do basic attribution models fail in Life Sciences buying cycles?
Put simply, much like the science behind discovery, Life Sciences marketing is rarely linear. Prospects don’t just show up on the first day of engaging with your content with a signed off RFP and a finished shopping list.
The path taken by Life Science prospects when considering a purchase is less like a ‘supermarket’ transaction and more like hundreds of separate trips to the library, archives and the professor’s clinic hours. There are shifting enrollment timelines, a labyrinth of prerequisite research touchpoints, and far more stakeholders involved in the purchasing decision, than you likely accounted for at the start. This process can last 18 months and longer, and marketers cannot accurately assess a prospect’s entire buying journey based solely on the last marketing or sales touch.
As already explored in our foundational guide to attribution models[2], the maths behind how we assign credit forms the foundation of your reporting engine. But in the context of the “Digital Disconnect” choosing a model isn’t just about calculations; it’s also about strategy.
Which attribution model works best for a long scientific buying cycle?
To track the decision-making journey in full, we have to move beyond simple ‘first-click’ or ‘last-click’ attribution models. Instead, we can use weighted rubrics to capture this long-form journey of decision formation, so let’s quickly review several common ways to approach this:
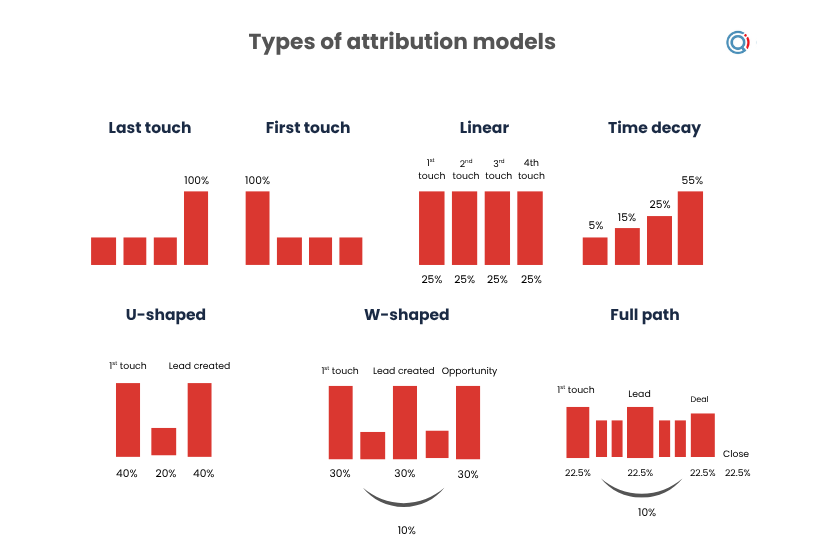
- U-shaped: Focuses 40% of the credit on the first touch and 40% on the conversion point. This is the so-called ‘Gatekeeper’ model useful for understanding which channels consistently introduce researching prospects into the buying journey. It works particularly well when your priority is understanding top-of-funnel performance and which channels consistently introduce qualified scientific audiences into the pipeline.
- W-shaped (the Biotech/Life Science gold standard): Adds a third (30%) peak for ‘lead creation’. In a 12-month cycle, this rewards the ‘mid-term’ technical validation stages such as engagement with webinars, protocol downloads, peer-reviewed application notes or requests for technical consultations; the moments that move a PI or researcher from passive awareness into active evaluation. Rather than focusing only on discovery or conversion, the model captures the slower process of scientific trust-building that moves a researcher from passive interest into active evaluation.
- Full-path: Tracks the entire buyer’s journey from first ad click to the final Purchase Order (PO), including engagement with the late-stage technical demos and sales interactions that close the deal. This approach is especially useful for organisations trying to understand how marketing, sales and technical support collectively contribute to revenue generation across long procurement cycles and multi-stakeholder buying groups.
Comparing approaches
Take a small but high-intent activity, like a scientist researching a topic a year ago, that only converts into a purchase now: weighted attribution can reveal that the real driver wasn’t a recent touchpoint, but that early research combined with academic funding finally becoming available in year two.
The W-shaped attribution rewards mid-journey activity like engagement with technical webinars, protocol downloads, validation-study engagement or requests for reagent compatibility data, but if that middle weighting is set to simply track any activity, rather high-intent signals, then this model quickly becomes distorted. A casual ad click or low-value visit can end up carrying the same importance as a meaningful technical interaction, such as a researcher downloading a validated assay protocol for use in an active experiment. The risk isn’t just inaccurate reporting, but in making budget allocation decisions based on misleading signals, directing spend towards activity that appears influential but in reality did not contribute to lead progression.
From the perspective of weighted attribution we can also see the importance that nuance can play. A small but high-intent activity that may have occurred a year ago when a scientist was researching and has now become a purchase, could in actuality have been a result of year 1 research work, and year 2 of academic funding finally made available.
This historical context is often essential for proving the ROI of content, SEO and technical education efforts that happened much earlier in the journey. Simpler attribution models tend to lose that continuity, making long-term influence invisible and potentially leading stakeholders to conclude that previous campaigns underperformed when, in reality, they were instrumental in shaping the eventual purchase decision.
| Model | Best for | Weakness |
| U-shaped | Awareness and lead generation | Underweights evaluation activity. |
| W-shaped | Scientific buying journeys | Requires good intent classification. |
| Full-path | Revenue analysis | More complex implementation. |
Why does attribution work differently in 18-month scientific buying cycles?
Scientific purchasing decisions involve long evaluation cycles, multiple stakeholders, and extensive technical validation.
If your attribution model relies solely on last-touch reporting, all the heavy lifting is done by your technical content and field teams is compressed into a single final interaction. Months of technical education, validation and trust-building are reduced to the click that happened immediately before the PO was signed.
Equally, forcing one attribution model across every reporting scenario creates its own distortions. A model designed to measure awareness is rarely the right model for evaluating technical validation content or sales enablement activity further down the funnel.
The objective is not to find one perfect source model, but to use the right model for the right question. Are you trying to understand what attracts new researchers into your ecosystem (U-shaped or first touch)? Or are you trying to prove the influence of your technical webinars, application notes and protocol resources on downstream purchase decisions (W-shaped)? ROI in Life Sciences is rarely static and context matters.
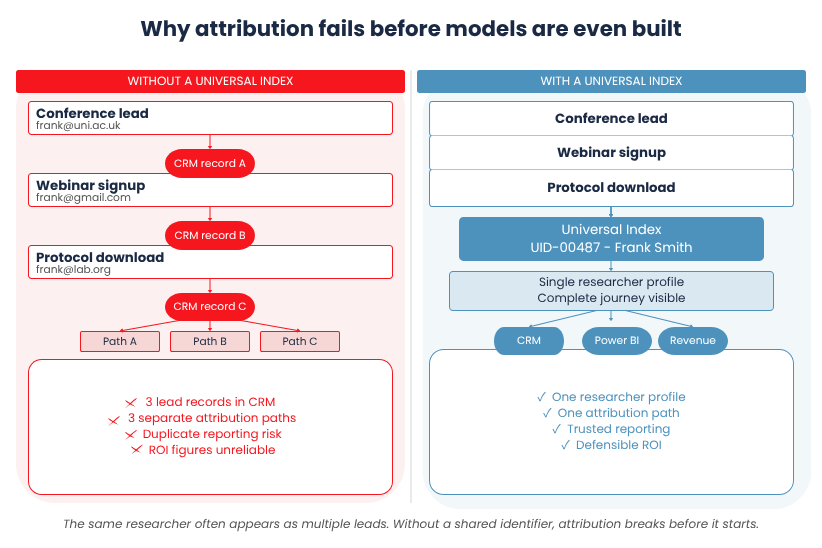
However, even the most sophisticated attribution model breaks down if your systems cannot consistently recognise the same individual across channels. You can build the perfect W-shaped framework for an 18-month journey, but if ‘Researcher A’ at a conference becomes a completely separate identity from ‘Researcher A’ on your website, your reporting quickly loses credibility. At that point, the issue is more about identity resolution and not attribution modelling.
To build a bridge between marketing, sales and commercial reporting, you need more than a grading system, you need to create your own Universal Index.

How to build a Universal Index so no lead gets lost
Before the Dewey Decimal System, libraries often used their own local filing structures. A researcher moving between institutions might need to learn an entirely new classification system simply to locate the same information. Attribution often suffers from the same problem. CRM platforms, marketing automation systems, event databases and regional content repositories all store fragments of the same buyer journey using different identifiers. Without a shared indexing system, those fragments cannot be reliably connected.
Much like the Dewey Decimal System that replaced the chaos of disjointed 19th-century library shelves with a single ‘Call Number,’ we need a Universal Index for our data. Without it, a ‘lead’ in the CRM is just like that book placed somewhere in the library without a reliable way for the rest of the organisation to find, track and contextualize it.
What are the main challenges of implementing attribution in Life Sciences?
The next challenge is creating a framework that keeps data consistent, accessible and trusted across teams. Let’s first look at the scenarios that complicate this type of set up, before sharing the step-by-step approach to implementing a data layer for seeing the big picture.
The identity crisis: Do you always use the same email for everything? No. Well researchers/PIs are no different to you and I in that respect. They might sign up to a webinar using their university email address, but then use their personal email to download a technical whitepaper a month later. With no identity resolution in the backend, your system now has two ‘Franks’ who are PIs researching mRNA at the Centre for Process Innovation when there’s actually only one.
The online/offline gap: ‘If it’s not on CCTV, it didn’t happen’. In an ideal world marketing would have its ear and eye on every interaction, phone call, email, webinar sign up, and conference conversation but in reality that doesn’t happen. Sales may have had a conversation with a prospect/lead at an industry event but because that person has not been uniquely identified and indexed, your universal index system is likely to fail. Prospect A has picked up a book from the library but we have no idea where he got the recommendation from, all we know is that he’s in the library actively reading that book.
The definition gap: Marketing and Sales exist to drive sales and in that shared purpose they are kindred spirits; soulmates. That said, they are soulmates from two different countries and (for the most part) with no lingua franca. Marketing may define a lead based on clicks whilst sales might consider a lead worth pursuing only when they have active grant funding.
To bridge the difference, science marketers need to stop tracking ‘clicks’ and start building the Infrastructure of Intent.
Having established the reasons behind data sorting, classification and attribution challenges in Life Sciences, let’s look at what you can set up for your team to help surface intent, and marketing ROI more easily.
How do you create a shared identifier strategy for Life Science leads?
At the centre of any attribution model is a deceptively difficult question: how do you reliably recognise the same researcher across dozens of interactions, systems and timeframes?
In practice, this is where many attribution strategies begin to break down.
Researchers move between institutional and personal email addresses, interact across online and offline environments and often reappear months later through entirely different channels. Without a shared identifier strategy, the same individual quickly fragments into multiple disconnected records across your CRM.
Several approaches can help reduce that fragmentation:
- Open Researcher and Contributor (ORCID) IDs: Often the strongest persistent identifier available in academic and research environments. When captured through webinar registrations, technical downloads or event interactions, ORCID can help anchor activity to a long-term professional identity. Realistically, however, not every researcher will provide one, particularly in early-stage engagement, so it should be treated as a valuable enrichment layer rather than a universal solution.
- Email normalisation and identity stitching: In platforms such as HubSpot, duplicate records are rarely solved through hashing alone. Effective identity resolution usually requires a combination of deduplication workflows, behavioural matching, standardised form governance and disciplined CRM management. Otherwise, one researcher quickly becomes multiple partial profiles spread across systems.

Define intent metrics and touchpoints
Not every interaction signals the same level of commercial intent. The challenge is determining which activities genuinely indicate scientific evaluation rather than passive engagement.
- Low-intent signals: Social clicks, ungated blog reads and newsletter opens may indicate awareness, but rarely reflect immediate purchasing intent in isolation.
- High-intent signals: Protocol requests, application-note downloads, reagent compatibility queries, technical webinar attendance or requests for validation data often indicate active evaluation behaviour. In a W-shaped attribution model, these are the interactions that typically deserve stronger weighting because they reflect trust-building and technical due diligence, not just visibility.
The important distinction is that intent scoring should never operate in a vacuum. A protocol download from a funded PI may carry very different commercial significance from the same action taken by a first-year PhD student. Effective attribution therefore depends not just on tracking activity, but on interpreting it within the context of role, timing and buying readiness.
How do you connect your CRM and BI tools for Life Science attribution reporting?
Don’t try to build final reports inside your marketing automation platform or CRM. Both are designed for execution, not for joining a LinkedIn click from 18 months ago to a purchase order signed last quarter. Instead, pull your data into a Business Intelligence (BI) tool like Tableau or Power BI.
Operationally, this requires:
- Set up scheduled data pipelines from your CRM (Salesforce/HubSpot) and Marketing Automation Platform (MAP) like Marketo/Pardot into your Business Intelligence (BI) tool. Most biotech marketing teams will need IT or a revenue operations consultant to configure this, so make sure you budget for it.
- Define a shared key before you connect anything. If your CRM and MAP don’t agree on what a “lead” is, your BI dashboard will show duplicates or gaps. Use the Universal Index (covered earlier) as your stitching logic.
- Start with one question, not a master dashboard. For example: “Which technical content sources (webinars, protocol downloads, application notes) appear in the 6 months before a purchase order?” Build that view first. Add complexity only when that one is stable and trusted by sales.
The goal isn’t a perfect single source of truth on day one. It’s a reporting environment where you can finally ask, “Did that 2025 LinkedIn campaign influence 2026 revenue?” and get an answer your finance and leadership teams will believe.
How do you set up tracking and intent weighting for scientific buyers?
Your Universal Index solves who the researcher is, but you also need to solve where they came from and how much that interaction is worth.
That means two parallel systems:
- Tracking (the “where they came from”): (Urchin Tracking Modules) UTMs, referral source capture, and offline-to-online bridges (QR codes, event lead scanning).
- Weighting (the “how much it’s worth”): A scoring framework that distinguishes casual browsing from active technical evaluation.
Both components require dedicated governance.
First, get your tracking infrastructure right
Before you can weight anything, you need to reliably capture the source of every interaction.
For digital channels: UTMs are non-negotiable. But UTMs without governance are chaos. If sales appends utm_source=linkedin and marketing uses utm_source=LinkedIn Ads, your reporting splits. Create a shared UTM nomenclature document before the next campaign launches. Check out our deep dive on UTM tracking for science marketers [3]. Make sure to assign one person (ideally in marketing operations) to enforce the standard.
For offline channels (conferences, symposia, booths): This is where most Life Sciences attribution breaks. No click, no track – right? Wrong, and here are three operational fixes:
- QR codes with unique UTMs on handouts, posters, or badges. When a researcher scans, you capture both the source (e.g., ?utm_source=SLAS2025&utm_medium=booth) and the timestamp.
- Open Researcher and Contributor ID (ORCID) or business card scanning at the booth. This gives you a persistent identifier you can match back to your CRM.
- Post-event form links in follow-up emails: “Did we meet at AACR? Enter the code from your badge.”
Without at least one of these, that conference spend is an expensive donation to the hotel, not a pipeline driver.
Second, build your weighting framework
Not all downloads are equal, consider for example a corporate brochure download and a validated protocol download. They may look identical in your CRM, but they mean very different things commercially.
Here’s a practical weighting framework you can implement in your MAP or CRM today:
| Interaction type | Starting weight | Why | Implementation note |
| Conference booth scan + QR code | High/Critical | Often the first verified touch in a long cycle | Create a dedicated lead source value (“Conference – High Intent”) |
| Technical webinar attendance (45+ min) | High | Signals active evaluation, not passive browsing | Weight these 3x a gated whitepaper download |
| Protocol download, application note, validation data request | Medium-High | Researcher is actively solving a problem | These are your W-shaped “mid-funnel” signals |
| ROI calculator or pricing page visit | Medium | Commercial intent emerging | Often appears 3-6 months before PO |
| Corporate brochure, general product page | Low | Awareness-stage only | Weight at 0.1x technical content |
| Social click, newsletter open | Low | Attribution source, not intent signal | Track for source influence, not lead scoring |
Critical operational note: 1) Weighting without factoring in decay is misleading. A high-weight interaction from 14 months ago matters less than a medium-weight interaction from last week, so make sure to set up time decay in your scoring model (one approach is to reduce weight by 50% every 6 months). 2) These are starting weights, not fixed scores. The same action can carry different weight depending on who performed it and what stage they’re likely at. A protocol download from a funded PI evaluating for purchase is not the same signal as the same download from a student doing background reading.
Align weighting with observed buying behaviour
Your MAP or CRM can handle weighting, and your BI tools can visualise the date, but none of this will work if sales and marketing teams don’t agree on what “high intent” means.
Before assigning any single weighing, marketers should sit down with their sales team and ask: “Looking back at the last five closed/won deals, what were the specific digital behaviours that happened in the 90 days before the first sales conversation?”
The answers become the foundation of your your weighting framework, which will need revisiting perhaps once every half a year until clear patterns start being observed. After that, a review should take place perhaps once a year to make sure that organizational knowledge is keeping pace with reality.
How to sync your CRM and BI tools to see the big picture
The objective of attribution is not reporting for its own sake. The objective is to create a system that improves decision-making by revealing which activities influence pipeline progression and revenue outcomes.
The honest answer is that attribution is never truly “finished”. Scientific buying journeys evolve, teams change, platforms change and researcher behaviour changes alongside them. But that should not be viewed as a flaw in the process. What you are building is not a static reporting dashboard but an operational feedback loop that allows marketing, sales and commercial teams to continuously refine how they understand influence, intent and revenue contribution over time.
Done properly, this moves attribution away from retrospective reporting and turns it into a decision-making system.
Test the model, don’t become loyal to it
One of the more common mistakes in attribution is treating a model as doctrine rather than interpretation.
Different attribution models answer different questions. A W-shaped model may reveal which technical resources consistently build evaluation-stage intent, while a full-path model may expose which activities actually correlate with closed revenue. Looking at only one view risks creating blind spots.
In practice, it is often useful to compare models side-by-side. For example, a technical whitepaper may appear highly influential in a W-shaped model because it repeatedly contributes to mid-funnel progression and lead creation. Yet the same asset may barely appear in a full-path revenue model because it rarely sits close to the final conversion event. That does not mean the content lacks value, but simply that its role is educational rather than transactional.
Conversely, this comparison can also expose “distraction” content that generates activity without contributing meaningful progression further down the pipeline. This is where attribution becomes commercially useful because it allows budget and effort to be redirected towards the resources that genuinely influence movement through the buying journey.
Align with sales, not just sales data
Earlier, we described marketing and sales as teams with shared goals but no Lingua Franca and that distinction matters operationally.
Marketing systems are generally good at recording what happened and sales conversations are often where you discover why it happened.
A technical protocol download, for example, may appear to be a strong buying signal based on historical scoring models. But conversations with sales may reveal that a large proportion of those downloads are coming from undergraduate students, early-stage researchers or academic browsers with no purchasing authority. Without that contextual feedback, marketing continues assigning high intent weighting to activity that may not reflect genuine commercial readiness.
This is where attribution becomes far more than a reporting exercise but a coming together over a shared interpretation framework between teams.
Over time, this alignment helps replace vague frustrations such as “marketing sends poor leads” with more measurable discussions around intent, qualification and progression. Sales gains visibility into how marketing scores and evaluates engagement. Marketing gains insight into the realities of procurement cycles, funding limitations and stakeholder behaviour inside active deals.
The result is not perfect agreement but a shared context.

What is incremental influence in Life Sciences marketing?
There is an understandable appeal to simple stories. “This webinar generated 100 leads” is clean, easy to report and reassuring to stakeholders. It validates the investment in the platform, the campaign, the travel budget and the team behind it. In resource-constrained marketing environments, that kind of clarity is seductive.
The problem is that Life Science buying journeys are rarely that simple.
Assigning absolute credit to a single interaction often creates a distorted picture of how decisions are actually formed. It gives us a visible moment to point at, but not necessarily an accurate explanation of what caused the outcome.
Take a familiar example. Imagine, that your team attends an industry conference and captures 150 leads with what appears to be an unusually strong conversion rate. On paper, the conclusion looks obvious: the event performed brilliantly. The natural reaction is to increase event spend, secure the same stand next year and double down on what appears to be a proven formula.

But this is exactly where a functioning attribution framework becomes valuable because it allows you to ask better questions.
- How many of those researchers had already engaged with technical content before attending the event?
- How many had downloaded a protocol, application note or validation study months earlier?
- How many were genuinely new opportunities, versus existing prospects who had already moved deep into evaluation before speaking to sales?
This is the difference between assigning credit and measuring influence.
Why incremental influence matters
In many cases, the event did not create demand so much as capture momentum that had been building elsewhere through content, webinars, nurture campaigns and technical education. Without that broader context, marketing risks optimising for the most visible interaction rather than the activities genuinely shaping intent over time.
The consequences are not theoretical.
If you over-attribute success to events, budget naturally shifts away from the slower, less glamorous work that originally built pipeline readiness in the first place. A year later, you return to the same conference expecting the same results, only to discover conversion rates have fallen sharply. The event has not necessarily become less effective. The upstream education and awareness activity feeding it has simply weakened.
That is why incremental influence matters so much in Life Sciences.
In long scientific buying cycles, marketing is rarely just the starting point or the closing interaction. More often, it is the steady accumulation of trust, validation and technical confidence that moves researchers closer towards decision over time.
The more useful questions therefore become:
- How much faster did this opportunity progress because the researcher attended the webinar?
- Did that protocol download reduce technical uncertainty?
- Which interactions consistently shorten the path from evaluation to purchase?
Those are far more commercially useful signals than simply deciding whether marketing or sales “owns” the lead.
Incremental influence gives you a way to measure contribution rather than visibility. And in a market where buying decisions are shaped gradually through evidence, validation and repeated technical engagement, that distinction matters enormously.

Key takeaways
- Standard last-touch attribution models systematically undervalue the slow trust-building that drives scientific purchasing decisions.
- W-shaped attribution which weights first touch, lead creation, and conversion, is the most appropriate starting model for 18 month Life Science buying cycles.
- A Universal Index (shared identifier strategy) is a prerequisite for any attribution model; without it, the same researcher fragments into multiple disconnected records.
- High-intent signals in Life Sciences (protocol downloads, technical webinar attendance, validation data requests) should be weighted 3x or more versus awareness-stage interactions.
- Attribution models should be tested against each other, not treated as doctrine because W-shaped and full-path models answer different questions.
- Incremental influence tracking (i.e. how much faster or further an interaction moved a deal) is more commercially useful than assigning absolute credit to a single touchpoint.
How do you build a reliable attribution framework in Life Sciences?
Difficulty tracking influence across long scientific buying journeys is not evidence that attribution has failed. It is a consequence of trying to measure complex purchasing behaviour across disconnected systems and teams.
There is no flawless attribution model waiting at the end of the process, but it is possible to build a framework robust enough to reflect how scientific purchasing decisions are made.
Without that in place, marketing teams have no choice but to default to the simplest stories available. Last-touch attribution, absolute credit and isolated campaign reporting become attractive options because they are easy to explain and to capture on a slide. But easy explanations can become expensive, because they obscure the slower accumulation of trust, validation and technical confidence that often determines whether a scientific buyer progresses towards purchase at all.
Final thoughts
Einstein famously remarked that everything should be made “as simple as possible, but not simpler.” That tension sits at the centre of modern Life Science attribution. The goal is not to simplify attribution until it becomes inaccurate. The goal is to create enough structure and consistency that influence can be measured with confidence.
One final note, is that working on such a project is not just about improving your reporting, it is also a highly strategic exercise. Organizations that understand their influence in the market most accurately are better able to allocate budget more effectively, align their sales and marketing teams and build stronger long-term pipeline health as a result.
If you’d like to understand where your own pipeline may be losing momentum, start with a free lead leakage audit. The Qincade lead leakage audit is a 30-minute diagnostic call that identifies where pipeline momentum is breaking down and what practical steps can close the gap. Book a free lead leakage audit.
References
1. Worden, L. / Market Diagnostics International (MDxI). Acquiring Lab Customers: Demystifying the B2B Sales Process. IVD Logix / BrandWidth Solutions. [https://brandwidthsolutions.com/blog/acquiring-lab-customers-demystifying-the-b2b-sales-process]
2. Qincade (2025). Attribution Modelling in Life Sciences: How to Measure ROI and Make Data-Driven Decisions [https://qincade.com/blog/attribution-modelling-measure-roi-and-make-data-driven-decisions/]
3. Qincade (2025). UTM Tracking for Science Marketers: The Why and How [https://qincade.com/blog/utm-tracking-for-science-marketers-the-why-and-how/]